13 Image-Based Rendering
main idea
图像 ->三维重建 ->新视角合成
Mesh#
- SfM 位姿求解
- MVS 深度计算
- Depth Fusion 点云融合
- Poisson Reconstruction 网格提取
- 纹理映射
传统流程局限
流程长、不可导,容易有累计误差、无法表示非常复杂的对象
Voxel#
Multi-Plane Image#
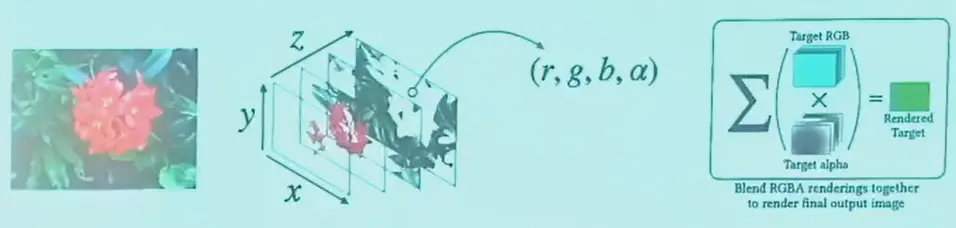
- MPI(Multi-Plane Image) 是一系列平行的图像,每一层都有 RGBA 四通道
- 可以渲染视角差异不大的情况下的新视角,视角范围较小
- 但是更加灵活,可以建模透明物体
Full RGB-Alpha Volume#
- pros
- 看起来更加真实,可以建模烟雾效果
- 渲染速度快
- cons
- 占用大量显存
- 无法渲染高分辨率图像
Implicit Representation#
NeRF#
- 实现了 view-dependent 效果,因为输入参数有观测方向
NeRF 为什么效果好?
- 表达能力强
- 重建方式更加稳定,不存在累计误差,端到端
NeRF 存在的问题
- 渲染速度慢
- 训练速度慢
- 几何重建质量低
- 无法建模大规模场景
- 无法建模光照变化
- 无法建模变化场景
- 降低渲染成本
- 降低采样点数量:NSVF, AdaNeRF, ENeRF
- NSVF,多建立了一个离散的 volume 记录哪里有物体,只采样 volume 中的
- ENeRF,渲染的点都在表面上,可以先用 MVS 知道表面在哪,在表面附近采样
- 降低点计算成本:SNeRG, PlenOctree, KiloNeRF, ObjectNeRF
- PlenOctree,对辐射场预计算,使用 octree 节省空间,使用 spherical harmonics 表示 view-dependent color,进一步节省空间
- 3DGS,用显式高斯球来近似连续的辐射场,splatting 是因为和光栅化操作很像
- 降低采样点数量:NSVF, AdaNeRF, ENeRF
- 降低推理成本
- Plenoxels,使用 PlenOctree 作为表示,每个点独立优化,加入正则项(相邻的相近)
- Instant NGP,将网络切分成很多小的 volume,存一个 feature,渲染时通过一个比较小的 mlp,用多分辨率和 hash table 来降低存储开销
- 降低训练迭代次数
- IBRNet,多视角下找一个特征点,直接将特征输入网络,预测这个点的颜色和密度
- MVSNeRF,想法类似
- 提升几何重建精度
- NeuS,NeRF 中加入了 SDF 的输出,但弱纹理、有反光区域仍然不好,可以用单目深度估计约束(如 MonoSDF)
- 表示无边界的场景
- NeRF++,将无穷远处表示为一个远球面
- MegaNeRF,每个区域用一个单独的 NeRF 表示
- 3DGS,点云本身就可以无限扩展,但需要 LoD
- 适应不一致的光照
- NeRF in the wild,对 NeRF 多一个光照编码的输入,甚至可以改变光照
- 同理,可以是时间的输入
- 建模动态场景
- 解耦场景表示,利用 3D 检测,对每个运动物体建一个单独的 NeRF,可以进行一些编辑
- Deformable NeRF,将一个在动的人重建成 canonical nerf 和 deformation field,分别记录标准 nerf 和变形,但只能估计小的形变
- Neural Body,对参数化人体模型进行建模