09 Deep Learning
Machine Learning#
- regression/classfication
- supervised/unsupervised
- train/test
Linear Classifier#
- 大型神经网络可以看成很多线性分类器
- e.g. 输入 32x32x3 的图像,分成 10 类
- 模型为:\(f(x)=W^Tx+b\)
- 其中 \(b\) 可以合到 \(W\) 中考虑
- 线性分类器,本质上是用一个(或多个)超平面分类数据点
MSE Loss:
但是这里的 \(f_W(x)\) 可能远超过 1,但也是正确的,所以需要 softmax 归一化到概率分布:
统计中常用 cross-entropy 衡量两个分布的差别:
Neural Networks#
为了适应非线性分布,引入非线性变换 \(f(x)=\sigma(W^Tx+b)\):
增加更多层:
如果没有 \(\sigma\),则可以直接展开,相当于一层,由此可以看出激活函数的作用。
层数多了不一定好:
- 参数量更大,表达能力更强,也需要更多训练数据
- 优化的时候存在梯度消失问题,计算复杂度增大,存在累计误差
CNN#
idea: 只看一个 patch 也可以识别一只猫,所以可以从局部提取特征
CNN 卷积核是权重共享的,这适应了图片的平移不变性,数学表达式为:
- 参数:size, padding, stride, dilation
- 输出尺寸:\((\text{img size}-\text{kernel size}+2\cdot\text{padding})/\text{stride}+1\)
CNN key idea
- 局部连接
- 权重共享
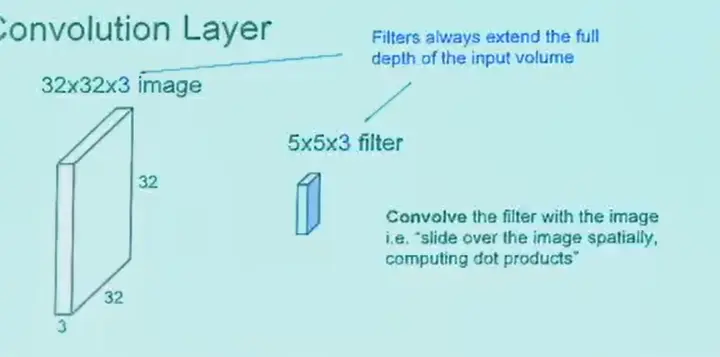
多通道卷积,卷积核也是多通道的。上图中的输出大小为 28x28x1。
多个卷积核,输出多个 feature map,通常 stack 在一起,例如 28x28x6。
卷积也需要激活函数,否则相当于一层。
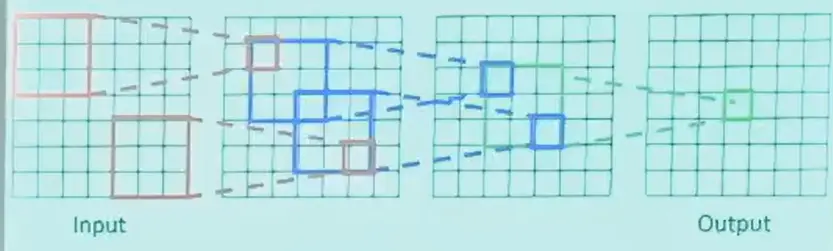
感受野是输出的一个 feature 对应原始图像的范围,层数越多,感受野越大。
实际上,为了快速减小 feature map 的尺寸,并聚合信息,会使用 pooling,一般有 max pooling 和 avg pooling。
Training Neural Networks#
定义一个 loss function:
使用梯度下降,或称为反向传播(back-propagation):
SGD(Stochastic Gradient Descent),每次只取一部分数据来计算梯度并更新参数:
Network Architectures#
Tip
Transformer 实际上是一个高效的 MLP
超参数一般是离散的,只能手工修改,修改超参数的目标应该是最大化测试分数(泛化能力)。
最规范的做法是分成三个 split,train/validation/test,调超参数的测试是在 validation 上进行的。
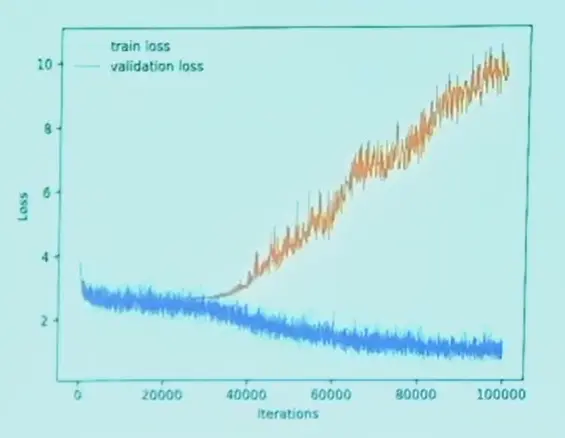
train loss 降低,在一点开始 validation loss 开始上升,说明模型开始过拟合,就停止训练。
为了避免过拟合,或者模型参数量过大训练数据太少,可以使用:
- 正则化,例如参数 L1 norm
- dropout,可以证明和 L2 norm 等价
数据增强(Data Augmentation),例如改变图片曝光、增加噪声、变形,可以增加数据量。
批正则化(Batch Normalization),网络的每一层输出的响应图可能非常大,为了让训练更加稳定,使用 batch norm:
一般是设定 \(\sigma^{(k)},\mu^{(k)}\) 两个可学习的参数。
ResNet 能够让在 0 初始化时至少不会变得更差,可以让网络层数很深。