10 Recognition
Semantic Segmentation#
语义分割

和 instance segmentation 的区别
语义分割只用知道这个像素是猫,实例分割需要知道是三只猫中的哪只猫
Sliding Window?#
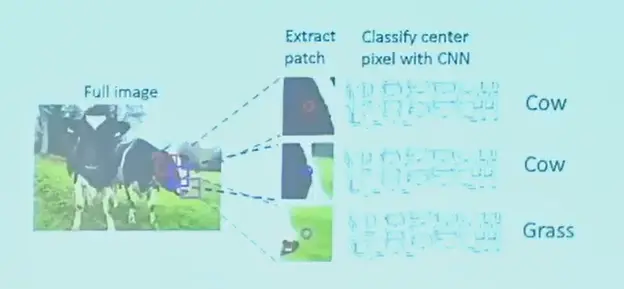
每个像素,取周围图像块,对这个像素进行分类。
问题在于
- 效率不够高,像素太多了,而且重复计算很多(滑动窗口重合)
- 信息是有限的,感受野太小了
Fully CNN#
- 尺寸不变,特征维度增加的卷积
- 可以每个像素做一个 softmax
U-Net#
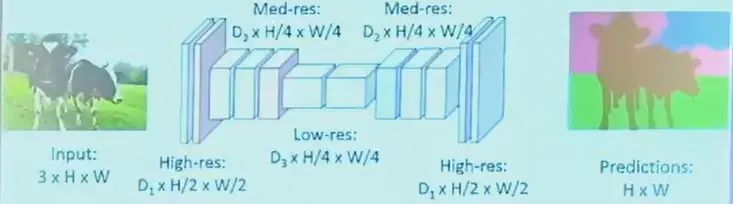
- 加 pooling 减小尺寸
- 插值增大尺寸
- 可以直接填 0
- 也可以线性
- 这里的 upsampling 由于有监督学习,是可以增加信息的,插值则本身不增加信息
Question
但 downsampling 的时候仍然有信息损失,U-Net 引入 skip connection
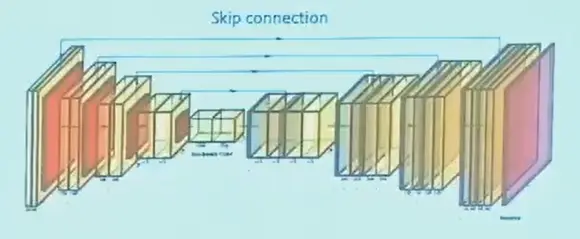
将先前此分辨率的 feature map 叠加,再做卷积。
DeepLab#
- FCN: 引入了 dilated conv,增大感受野而不增加参数
- CRF: 在 feature map 上引入空间约束(类似 Markov Random Field)
Evaluation Metric#
Per-pixel Intersection-over-union,越接近 1 越好。
\[
\text{IoU}(\text{obj})=\frac{\text{area}(\text{obj}_\text{gt}\cap\text{obj}_\text{pred})}{\text{area}(\text{obj}_\text{gt}\cup\text{obj}_\text{pred})}
\]
Object Detection#
- input: RGB image
- output: a set of bounding boxes that denote objects
- class label
- location
- size
- 框的输出是不同意的,每一张图中可能有不同个数的物体
Sliding Window#
- 用滑动窗口去扫描,输入网络
- 但是需要很多不同大小的框,不太可能
R-CNN#
可以使用 Region Proposals

- 先找到一些可能的 patch/box
- 然后再过网络,需要 resize 到网络的输入大小
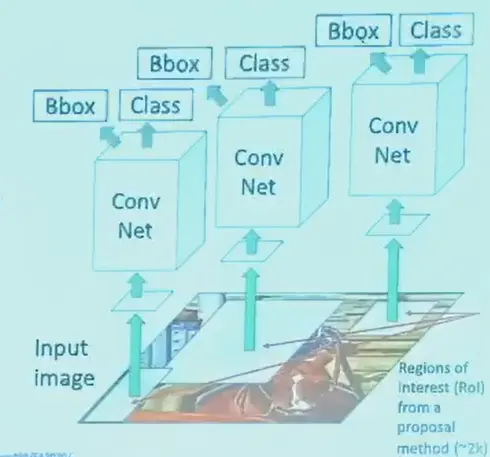
- 称为 Region-CNN,大概会选择 2000 个框
- 损失函数,label 用 cross-entropy,位置和尺寸可用 L2
Non-Max Suppression#
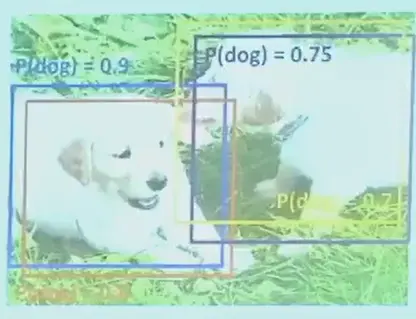
对每一个类别,选择 score 最大的框,删除同一类别中其他 IoU 较高的
如何提高检测速度
- 避免重复计算
- 减少框数量
Evaluation Metric: IoU#

- 位置同样使用 IoU
- 一般来说,IoU 大于 0.5 比较好,大于 0.7 非常好,大于 0.9 几乎完美
- label 用 cross-entropy
Fast R-CNN#
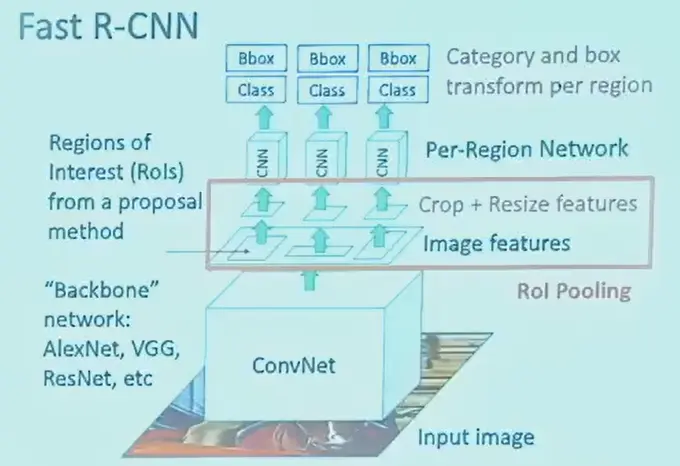
- 卷积网络中有很多层,可以先统一过一些层
- 前面整张图都要过的称为 backbone 主干网络
- 然后将 region 中的特征取出,pooling,再过后面的网络
Faster R-CNN#
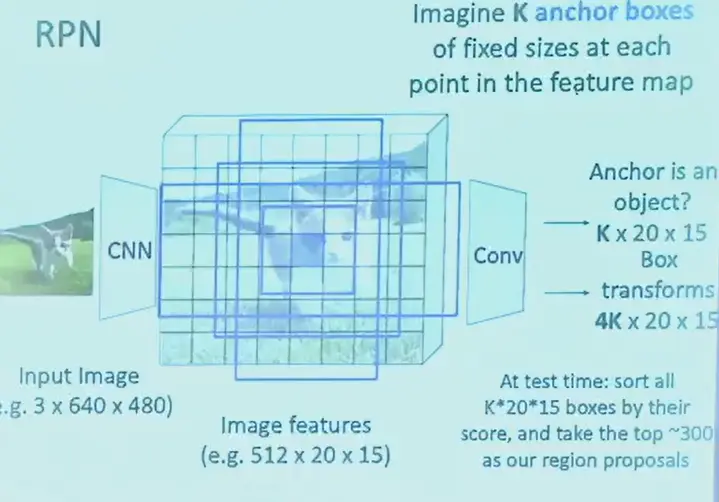
- 生成 region proposal 也用了卷积网络,Region Proposal Network (RPN)
- 输出的是可能的框的 feature
- 对于最终 feature map 的每个像素位置,预先定义 K 种可能的 bounding box
- 输出的 feature 包含 K 种框的 score 和对于框的位置、大小的微调数字
- 相当于 feature 有 \(K+4K=5K\) 个 scalar
- 然后使用其他网络对框进行准确性判断和 labeling
Question
但是速度仍然不够?这些方法都是两阶段目标检测。
Single-Stage Object Detection#
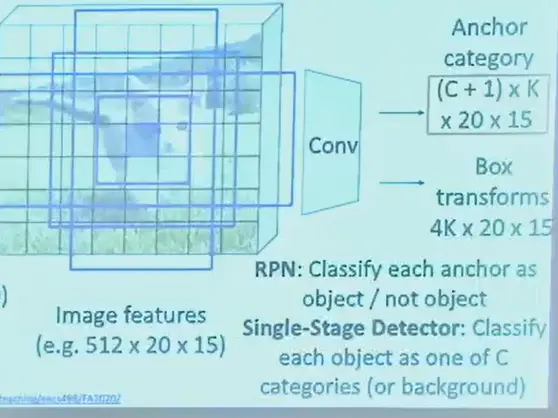
- 直接输出 K 个框的 class label 概率分布
- e.g. YOLO(you only look once) 速度快,准确率也足够
Instance Segmentation#
在 Object Detection 的基础上,输出一个 mask,判断前景还是背景(逐像素分类)
Deep Snake#
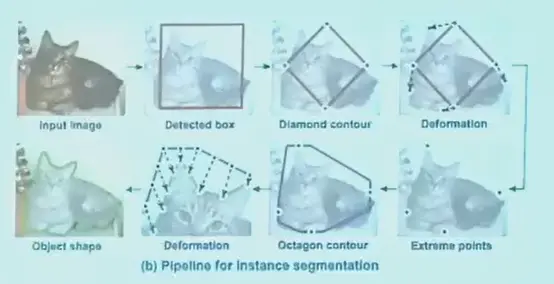
- snake
- 初始有一个框
- 将框视为一些点的集合
- 优化目标是,点所在的位置梯度比较大,左右两边特征不同
- deep snake 就是将这个过程交给神经网络完成
Panoptic Segmentation#
全景分割,语义分割和示例分割的并集
Human Pose Estimateion#
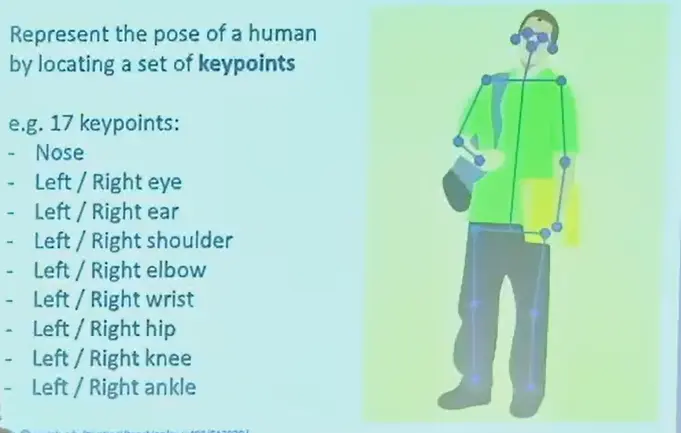
用人体的关键点来表示人体姿态。
Single Human#

直接让网络输出这 17 个点的位置,网络表现不好。
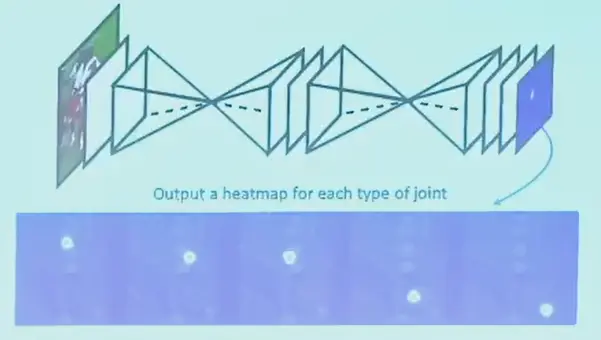
使用热力图,希望输出 17 个热力图,每个图表示一个关键点的位置,可以使用 CNN 去做了,也可以是 U-Net。
Multiple Human#
- top-down
- 先用 YOLO 找到所有人的 bb
- 再把每个 bb 过热力图网络
- 但如果 YOLO 将两个人框在一起了,第二步无法修正
- e.g. Mask R-CNN
- bottom-up
- 先检测所有可能的关键点
- 再组合成人的骨架
- e.g. OpenPose
- 同时会输出一个相关性向量场(Affinity Fields),说明这个关键点最可能往哪个方向的连接,尽量避免歧义性
Note
bottom-up 更快,有遮挡场景时也会更好
Other Tasks#
Video Classification#
- input: 4d array
- 也可以卷积,但速度会很慢
Temporal Action Localization#
- 在时间维度上,对人的动作进行分类,例如方便查询走路的时间。
- 将视频切分成片段,分别进行分析。
Spatial-Temporal Detection#
- 时间和位置维度上对人的动作进行分类
Multi-Object Tracking#

- 每一帧得到框,然后通过特征、光流等方法与上一帧的匹配
- 光流,前后帧特征匹配,或者另一个神经网络