11 3D Deep Learning
Deep Learning for 3D Reconstruction#
Feature Matching#
SfM 第一步就是特征匹配
使用 DL 来直接预测相机位置?
- 精度远低于 sfm
- 只适用训练使用的场景
Recap: Feature Matching#
- detect
- describe
- matching
Why DL?
场景曝光变化、时间变化,描述子无法实现
Example: SuperPoint#
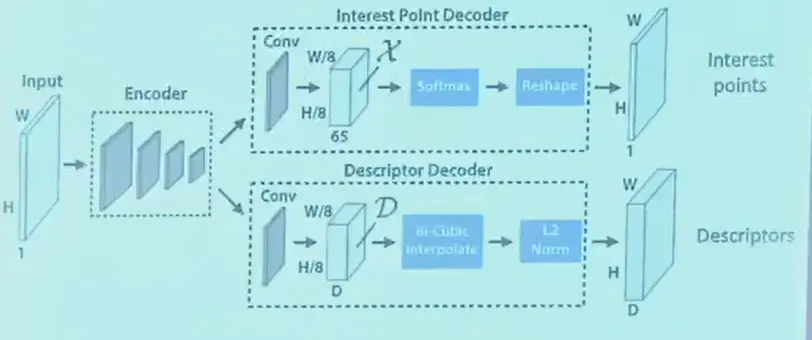
- 同时输出特征点热力图和特征图
- 热力图
- 根据 gt 构造热力图作为监督
- 实际上 gt 不好定义,是用 mesh 合成的数据,例如角点;或者对一张图进行单应变换
- 训练准确性,找到关键点,\(L_\text{loc}=\sum_i||\mathbf{p}_t^*-\hat{\mathbf{p}}_t||_2\)
- 训练可重复性,进行变换,\(\min_f\frac{1}{n}\sum_{i=1}^n||f(g(I))-g(f(I)||^2\),变换前后输出的点是同一些点

- 描述子
- 用 CNN 的特征来作为描述子
- 两张图都过描述网络,gt 的一对描述子应当尽量接近,假设 A 和 P 匹配,和 Q 不匹配
- \(L_\text{pos}=\frac{1}{N}\sum_{i=1}^N||F_I(A)-F_{I'}(P)||^2\),希望描述子完全相同
- \(L_\text{neg}=\frac{1}{N}\sum_{i=1}^N\max(0, m-||F_I(A)-F_{I'}(Q)||)^2\),希望描述子足够远,\(>m\)
- 数据可以来自 MVS,这里的逻辑是,可以用 MVS 进行视角相近的重建,但用视角差别较大的来训练网络
Object Pose Esitmation#
求解物体在相机坐标系下的位姿
Application
- 单目物体抓取
- 无人驾驶
- VR 试衣

找到物体三维点到视图二维点的对应关系,然后求解 PnP 问题即可。
Feature-Matching-Based Methods#
- 先根据一系列图像重建物体的三维模型
- 对于 query image,和三维模型进行特征匹配即可
Question
但是物体有反光、纹理少的情况下,SIFT 不能满足
Direct Pose Regression Methods#
- 先目标检测,得到 bb
- 然后根据 bb 得到 6 自由度位姿
Question
估计精度不高
Keypoint Detection Methods#
- 类似人的姿态,对三维模型定义一系列关键点
- 用 CNN 检测关键点的二维位置
- 然后 PnP
3D Human Pose Estimation#
需要得到每个关键点的坐标
Application
- 足球越位判断
- 动作捕捉,替代 MoCap 专业系统
- method
- 多视角拍摄,每个视角检测二维关键点位置
- 三角化计算三维关键点位置
- more about
- 单目相机恢复骨架
- 使用参数化人体模型,让网络估计模型的少量参数
Dense Reconstruction#
pipeline
- 计算每张图的深度 MVS
- 将深度图转换为三维表面 Poisson Reconstruction
- Texture mapping
传统 MVS 的问题
- 无纹理区域
- 反光和透明
- 重复的图案(如护栏)
Learning MVS#

和传统 MVS 的不同之处
- plane sweep -> cost volume 使用了 feature map 来计算
- 使用网络来求解 depth
是否可以直接优化三维网格/纹理
- 渲染过程并不是一个可微分的过程
- 网格本身初始化比较困难,如何得到一个好的初始猜测解
- 网格的拓扑结构会在优化时被破坏
Recap: Implicit Representations#
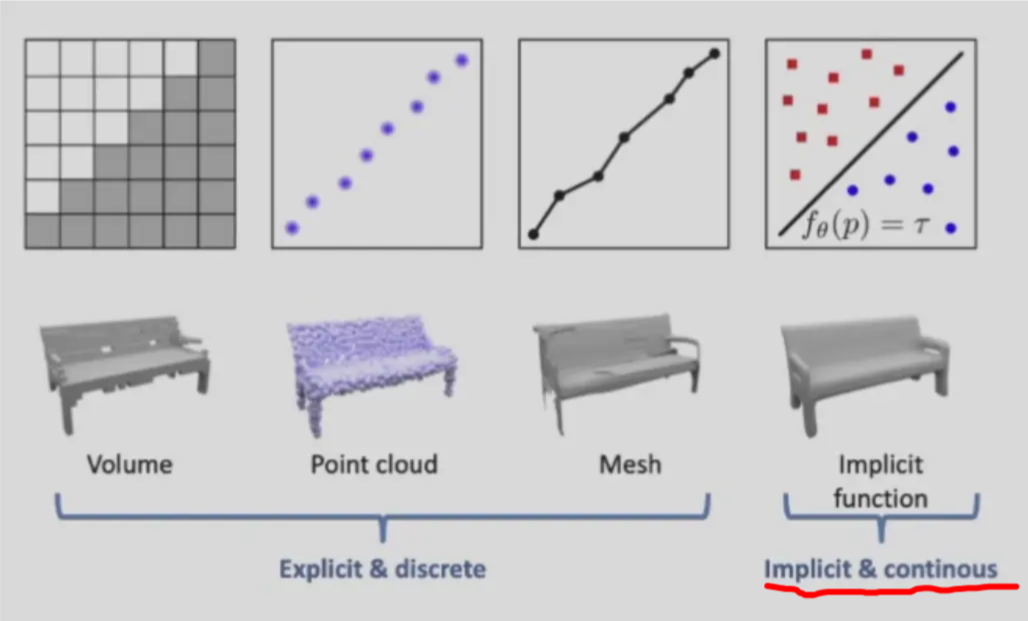
隐式表示可以是一个复杂的函数,因此可以使用 NN。
NeRF#
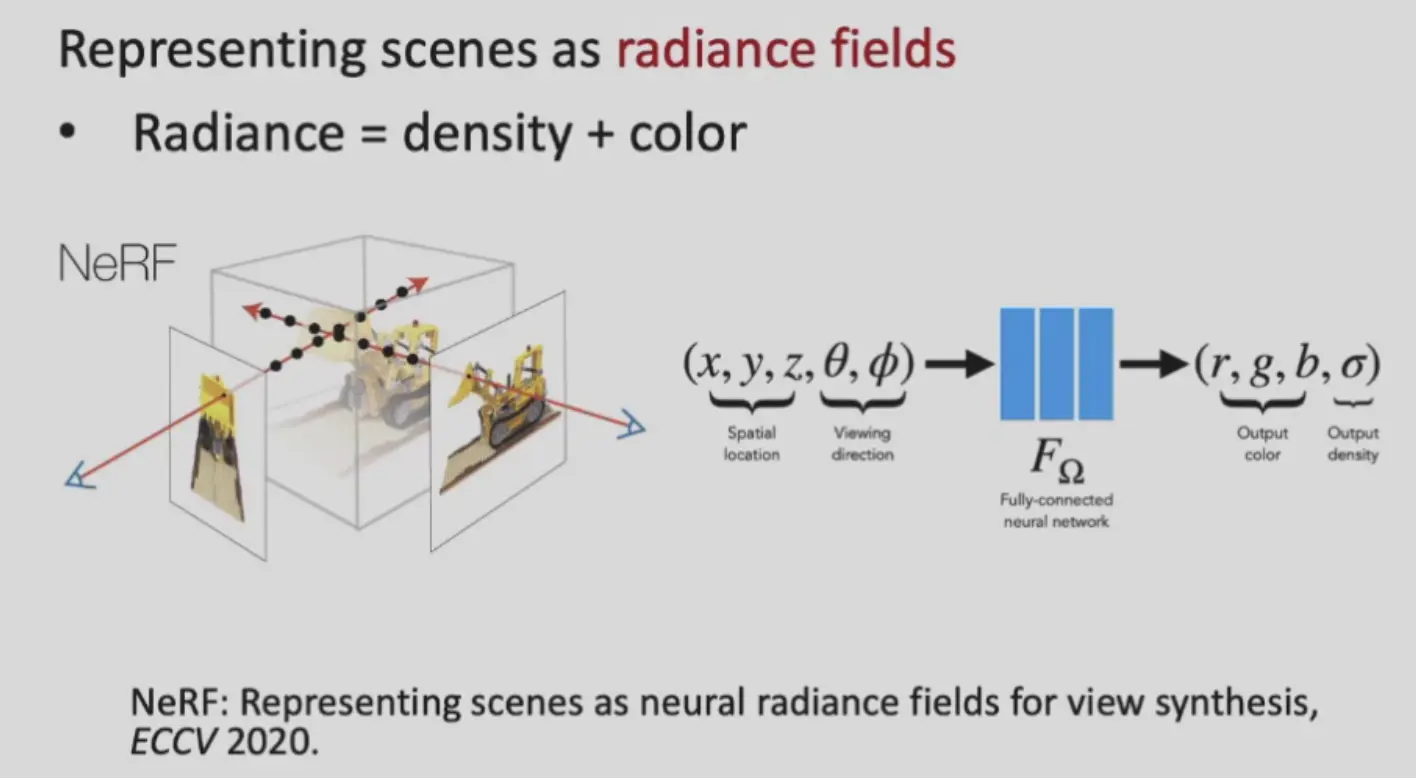
NeRF 使用 volume rendering,即使用射线穿过场景,采样使用网络得到点和 sigma,加权求和,这是一个可微的操作。
Question
本质上是一个 volume 表示,使用 marching cubes 重建表面噪声很大
NeuS#
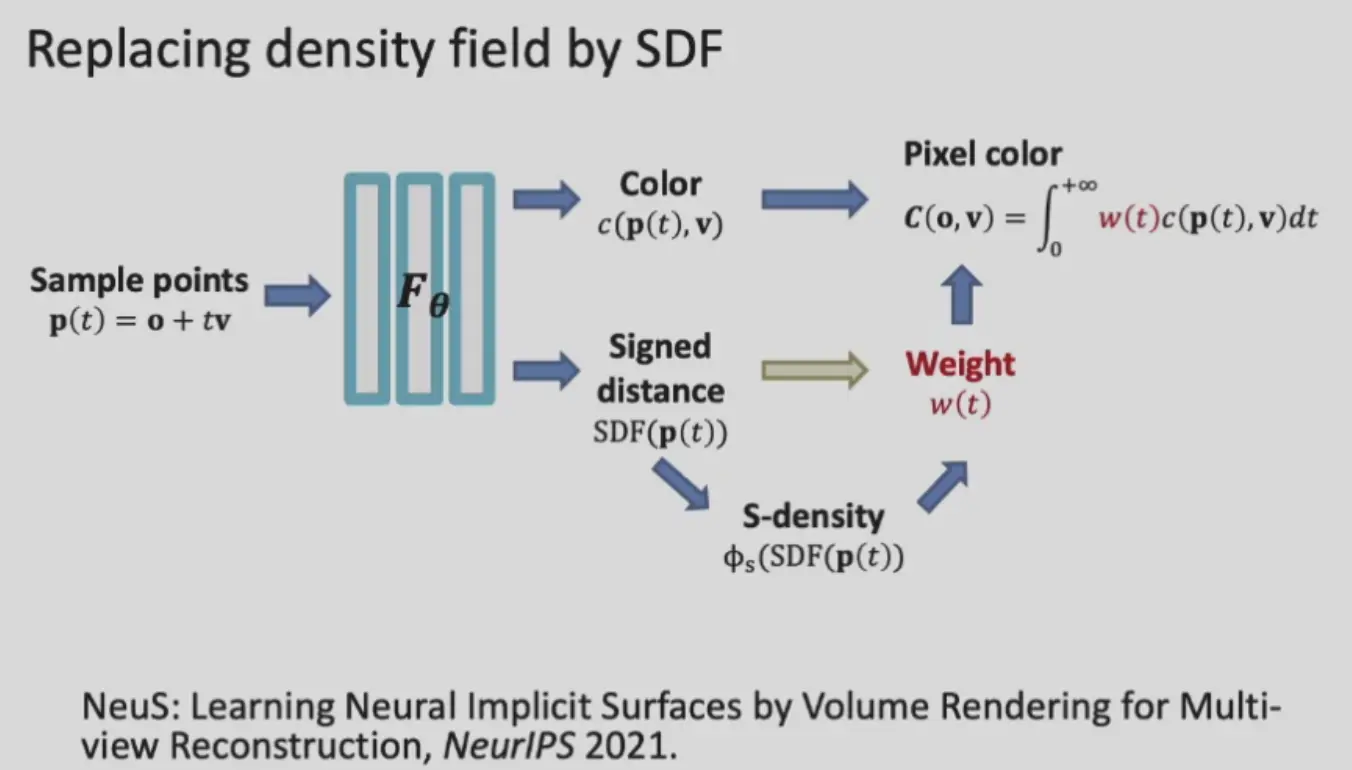
使用 SDF 来表示表面,设计 S-density 公式来表示 sigma(density) 的值,使之也可满足 neural rendering 流程。显然,距离表面越近,density 越大。
Single Image to 3D#
Monoculer Depth Estimation#
- 数据来源
- cg 引擎
- 深度相机
- 多视图重建高质量图形再求深度
- 单目深度天然存在歧义性
- 对于同样的输入,希望网络有不同的输出
- 需要使用归一化后的损失函数,scale-invariant
Standard L2 error:
这里的 \(\log\) 可以不让误差被远的主导。
Scale-invariant depth error:
即假设每张图都存在一个未知的尺度,\(\alpha\) 能够确保预测深度同乘一个数,loss 不变。
3D Generation#
- 大部分输出一个 NeRF 而不是 mesh
Deep Learning for 3D Understanding#
3D Classification#
- input: 3d model
- output: class
Image: Multi-View CNNs#
- 用 mesh 生成多角度图像
- 用 CNN 分类,投票
Volume#
3D ConvNets#
- 如果输入是 volume 表达,可以在三维上进行卷积
- 问题是卷积很慢 \(O(N^3)\)
如何加速三维卷积计算?
三维 volume 表示和二维不同,大部分空间可能都是空的,可以稀疏卷积 Sparse ConvNets
Sparse ConvNets#
- 使用 octree 来表示 volume,能够很快检测到哪里没有值(剪枝),于是可以跳过
- 同时,由于卷积会导致信息的“扩散”,随着卷积的进行,volume 会更加密集,因此只限制在原来有 volume 的位置有输出
Point Clouds#
Point Net#
point clouds is unrasterized data,不在格子上
Challenge & solution
- 点云是没有顺序的:每个点单独 mlp,然后 pooling,再过 mlp
- 应当具有旋转不变性:所有点经过另一个旁路网络 T-Net,来将物体摆正,T-Net 没有单独训练
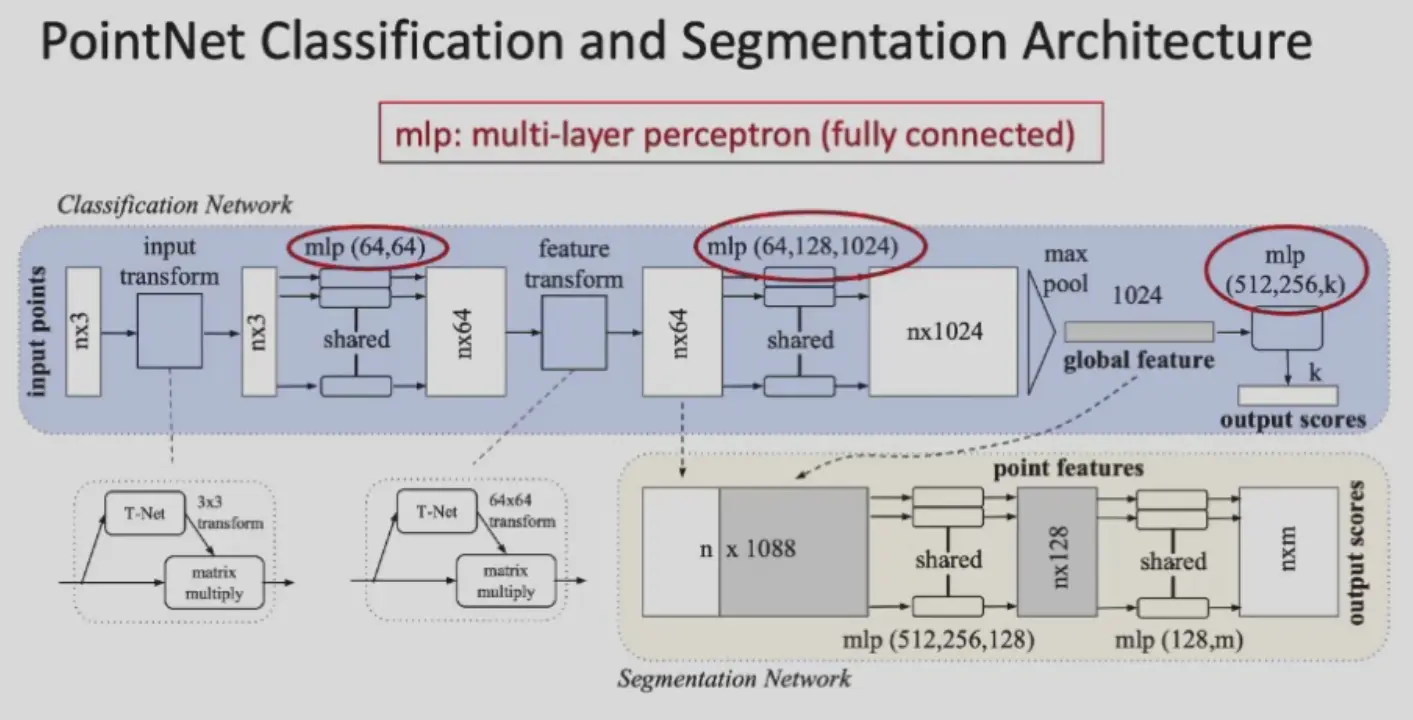
- pipeline
- 先过 T-Net 得到修正后的点云
- 每个点都过 mlp 提取特征,特征变换等,pooling 得到全局特征
- 分类:使用全局特征进行分类
- 分割:将每个点的特征都拼接上全局特征,过 mlp 得到这个点的 label
Question
PointNet 直接整个模型 pooling 了,没有递增的局部的感受野
PointNet++#
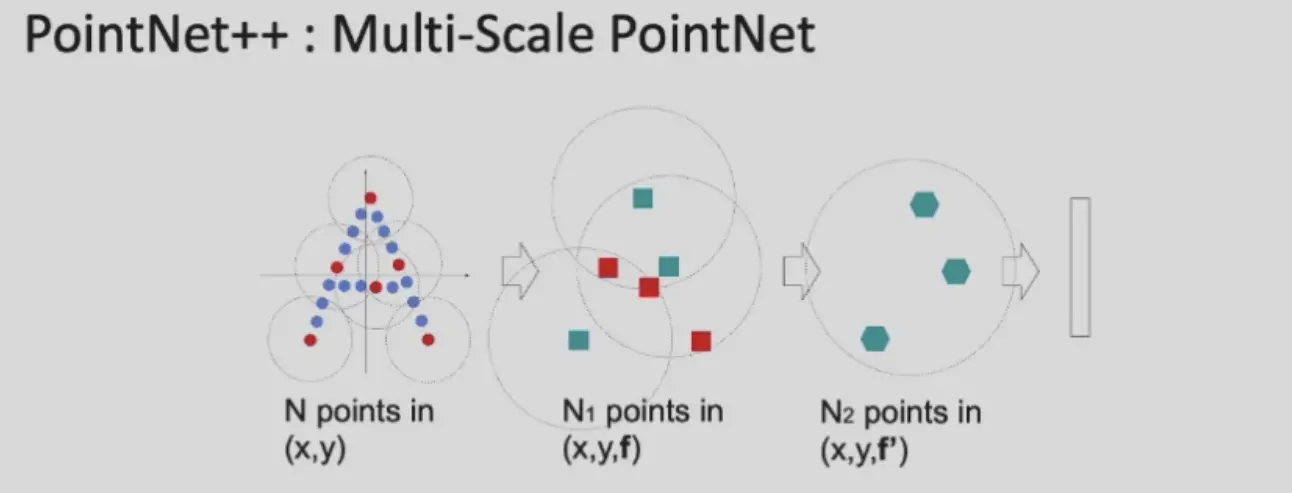
引入 local pooling 机制
- 使用 Fartherst Point Sampling (FPS) 采样 anchor points
- 找到所有 anchor points 的 neighbourhodd
- 进行 maxpooling,继续其他的 PointNet 操作
3D Semantic Segmentation#
- MVS 先渲染到二维图像,进行二维分割,再 fuse 到三维,可能需要投票
- 或使用 PointNet++
3D Object Detection#
找到物体三维的 bb,一般坐标是 bb 中心,还有长宽高和旋转
Question
同样,如果使用滑动窗口,候选框会非常多
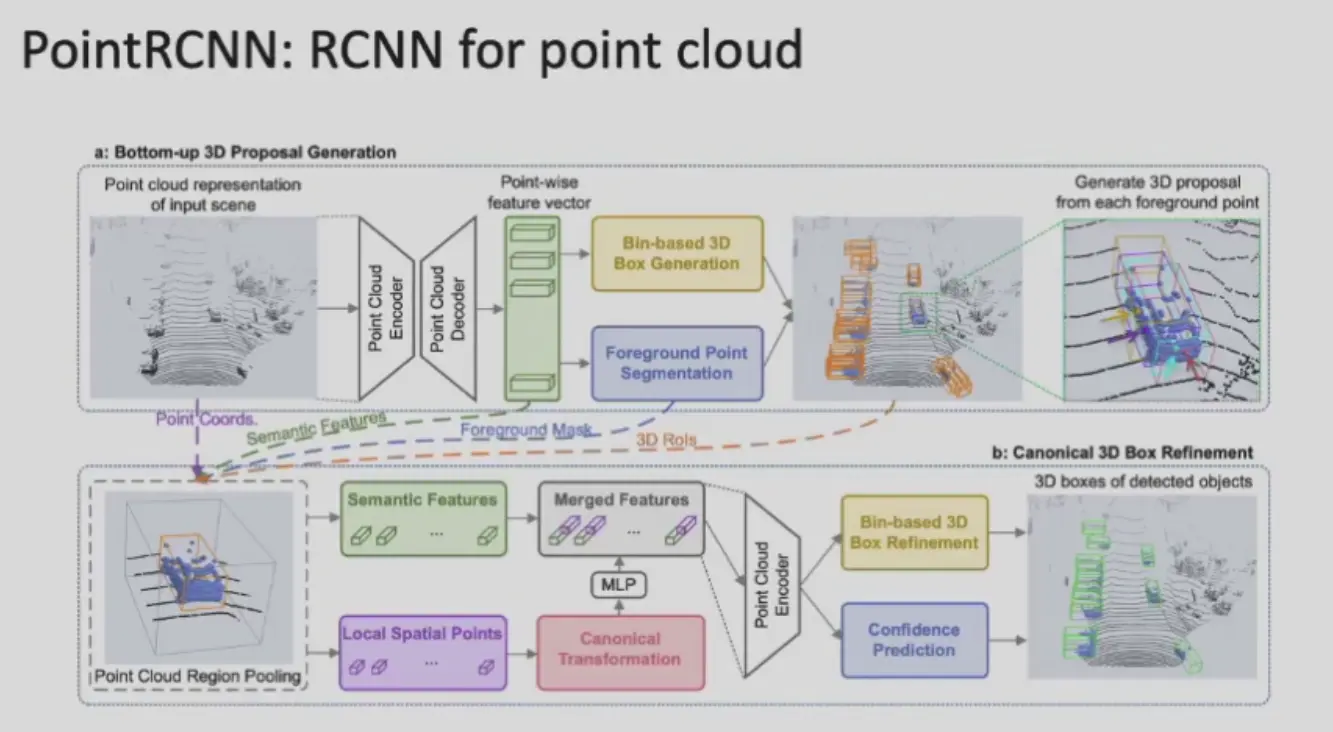
PointRCNN#
key insight
- 3D 上物体几乎不会重叠
- 只用将前景和背景分割开,前景再点云聚类,就是 proposal
Frustum PointNet#
先进行二维检测,得到一个视锥 frustum,用来截取点云,得到 proposal
3D Instance Segmentation#
- top-down: 也可以在 3D detection 中得到框,再进行分割
- bottom-up: 进行聚类,自然得到分割
Datasets for 3D Objects#
Problem
3D 领域缺少高质量的数据集 #CS/CG-CV/Dataset
- ShapeNet: 大量合成的数据集
- 材质用的都是纹理贴图,比较假
- PartNet: 在 ShapeNet 的基础上提供了分割的 gt
- SceneNet: 合成的场景数据集
- ScanNet: RGBD 相机重建得到
-
如何求解相机位姿
- 用 RGB 图像 SfM
- 用两个局部点云求解,点云匹配,反而比较难
-
- KITTI: LIDAR 智能驾驶数据,bb,点云
- Semantic KITTY