12 Computational Photography
High Dynamic Range Imaging (HDR)#
Exposure#
- gain 和 iso 有关
- irradiance 与光圈有关
- time 受快门速度影响
单反相机没有快门延迟,因为不需要将传感器的电荷清零。
Dynamic Range#
the ratio between the largest and smallest values of a certain quantity (e.g., birghtness)
使用包围曝光得到高动态范围图片。
Image Formation Model#

- 舍弃太亮和太暗的像素
- 对于剩下的像素,按照曝光时间的倒数加权平均
- 得到新的像素点
Tone Mapping (Gamma Compression)#
将高动态范围的图像映射到低动态范围空间
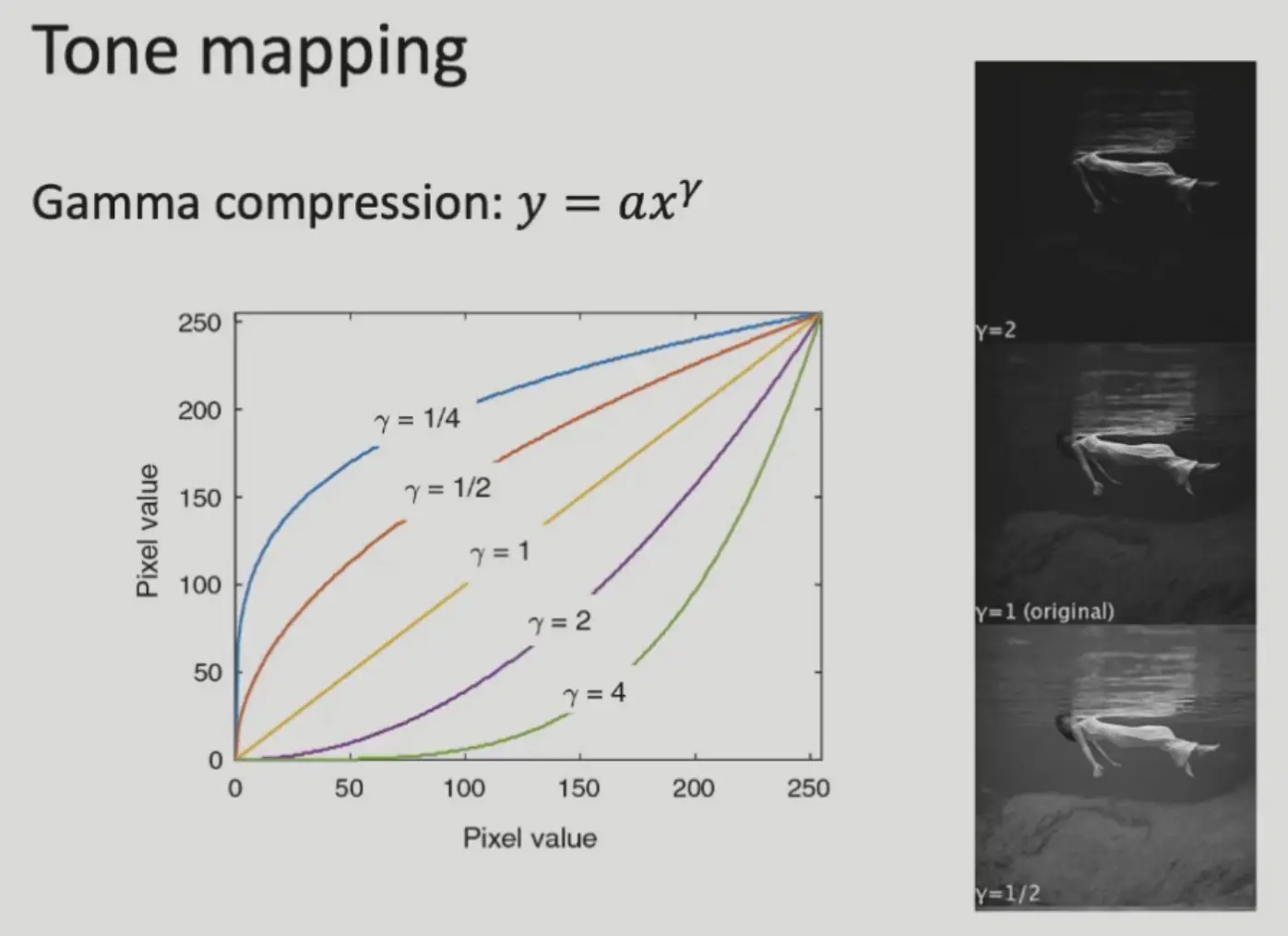
不同的相机可能会用不同的 gamma 曲线,所以需要保留 raw 文件。
Deblurring#
- motion blur: 物体或相机移动
- ps 有去运动模糊的功能
Modeling Image Blur#
- 焦外模糊,每个点都变成光斑,即高斯模糊,相当于清晰图像经过高斯核卷积
- 形状取决于光圈的形状
- 运动模糊,也可以是卷积,每个点都变成一条线,相当于清晰图像经过这个模糊核卷积
- 形状取决于曝光时间内相机视角的移动

所以要去卷积(deconvolution)。
Non-Blind Image Deconvolution#
根据卷积定理,时域上的卷积 = 频域上的乘积,若 \(G\) 为模糊图像,\(F\) 为清晰图像,\(H\) 为模糊核,则:

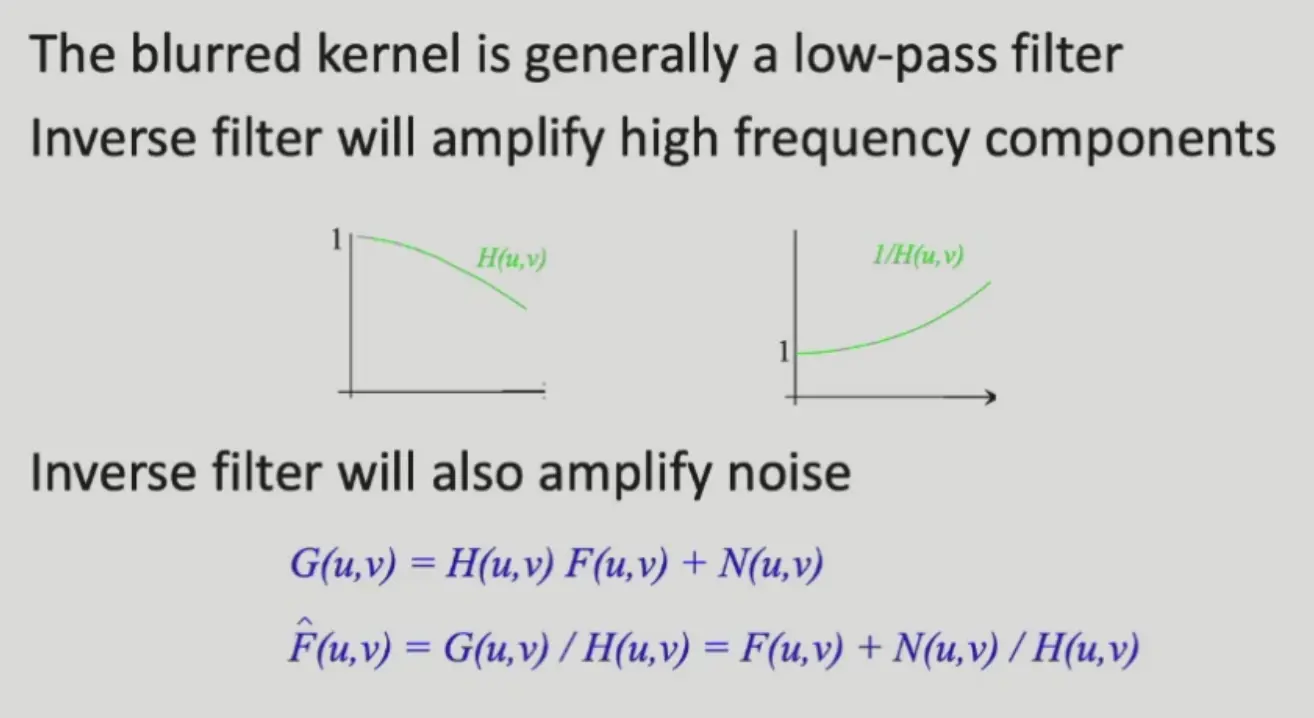
图像太模糊的时候,这种方法效果非常差,这是因为:模糊核比较大的时候,其傅里叶变换(也是一个高斯分布)会变小,0 的部分变多,而距离原点比较远的高频信息除以 0 被放大很多倍。
Question
如何尽量不放大高频噪声?

重新设计模糊核的傅里叶变换的倒数:
这被称为维纳滤波器。
Application
- 高速路上,模糊核基本已知,可以恢复车辆的运动模糊
- 哈勃望远镜的镜片有偏移,用滤波修复
Optimization Method#
模糊图像的生成过程:
优化目标为 \(N\rightarrow 0\),即:
但是这个方程的解不唯一,有多种 \(F\) 和可以满足条件。
加入约束条件:图像的大部分都是光滑的(梯度是稀疏的),做一个梯度的 L1,变为:
Blind image Deconvolution#
卷积核也要纳入优化,而且增加先验:卷积核也是稀疏的(是线组成的):
Colorization#
将黑白的图像变成彩色的
Sample-Based Colorization#
use sample image

- 对于每个像素,匹配到 sample image
- 将匹配到的像素颜色赋值过来
Interactive Colorization#

对于两个相邻的像素,如果亮度接近,颜色也应当接近:
- 另外约束用户已经输入的像素颜色不变
- \(w_{rs}\) 衡量了 \(r,s\) 之间的相似度
对视频上色?
打关键帧,一小段内用相同的先验来优化
CNN#
- 输入黑白图,输出彩色图
- 同样的输入有不同的 gt,例如不同颜色的猫,所以直接用 MSE 会造成崩溃
GAN
将损失函数定义为一个神经网络
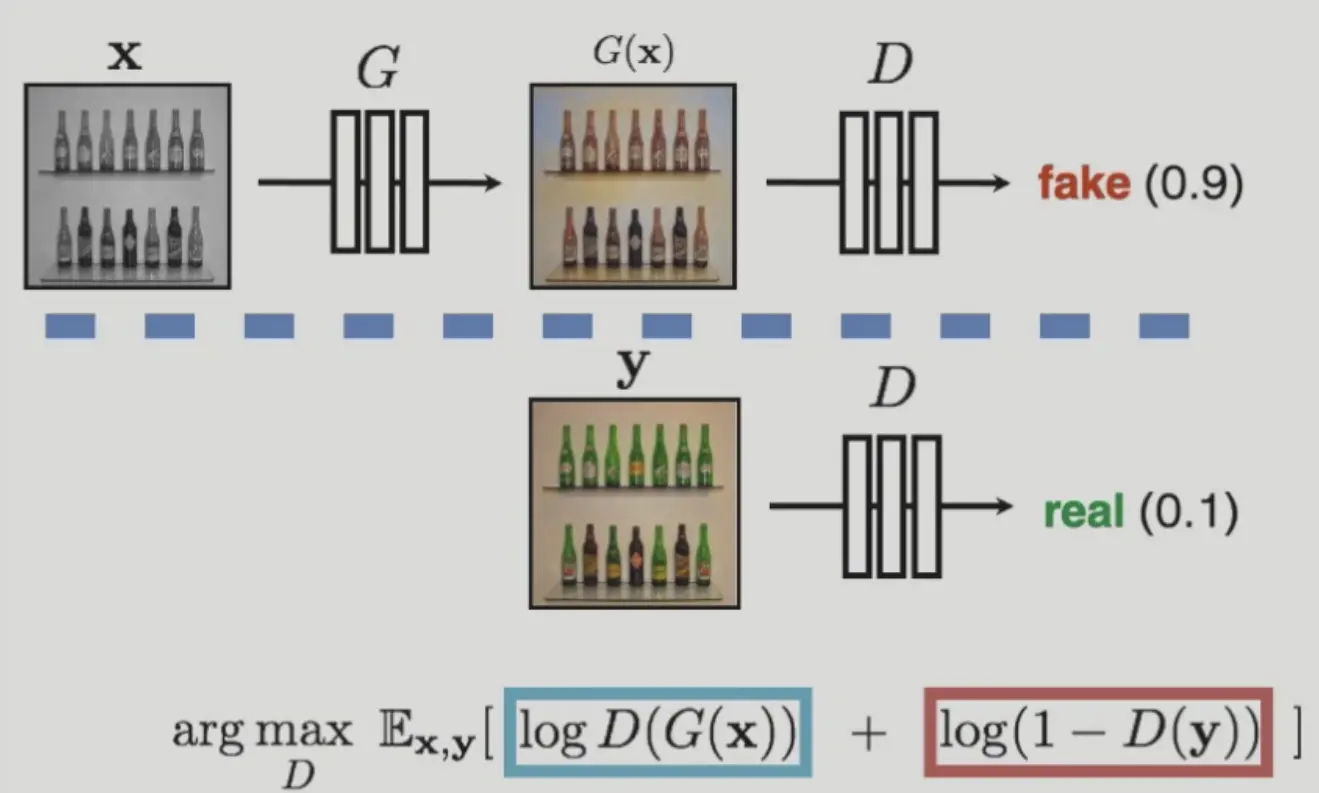
GAN 的优化方案:
可以迭代优化,固定一个训练另一个。
Question
minimax 问题训练时非常容易发散
Question
如果仍然需要保留用户输入的部分控制,可以加入一个 mask 输入,是用户的 brush 图层
More Image Synthesis Tasks#
Super-Resolution#
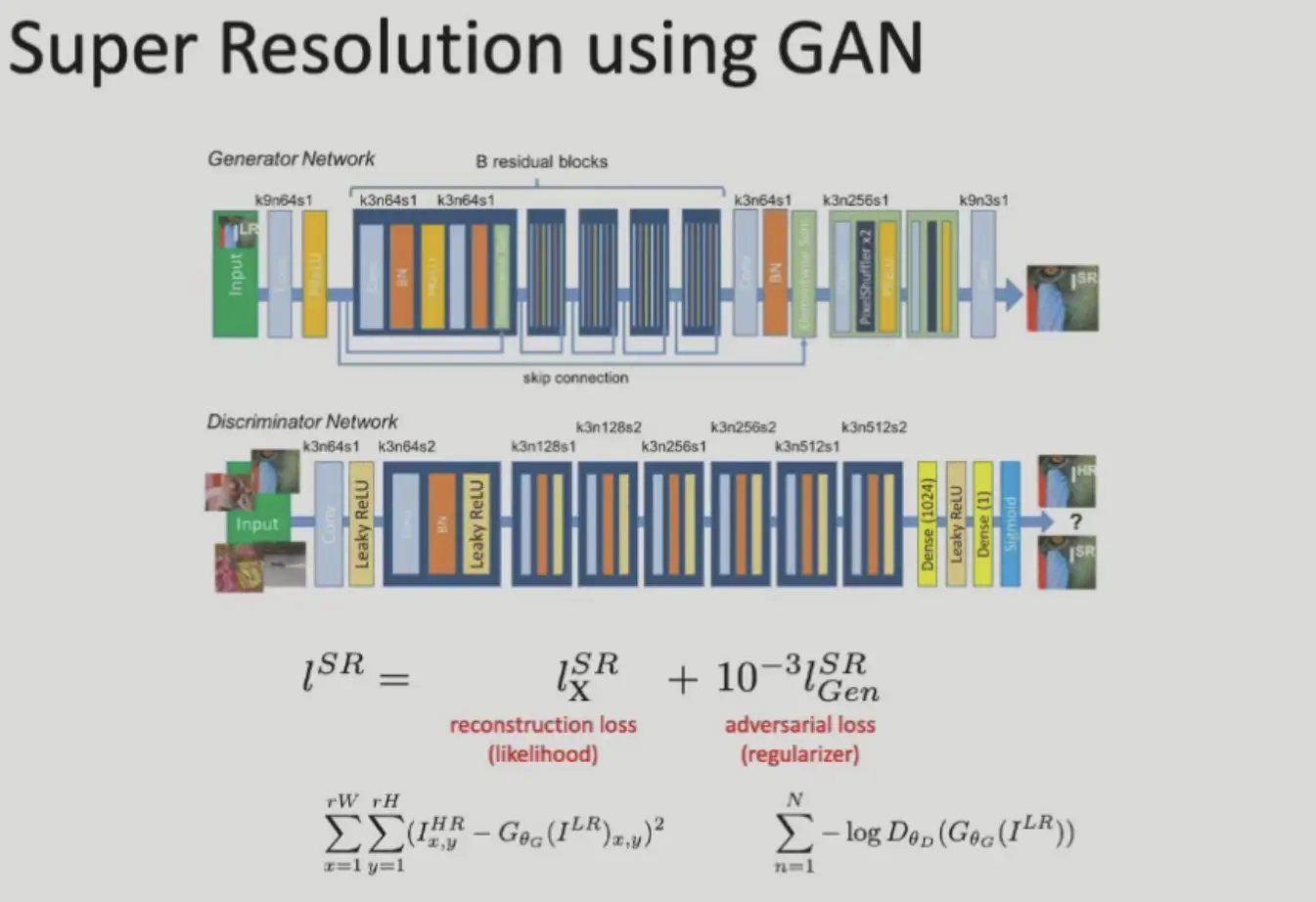
loss 分为两部分,一部分与原图保持一致,另一部分是 GAN。
Image to Image Translation#

- 风格转换、草图生成、去雾
Pose and Garment Transfer#
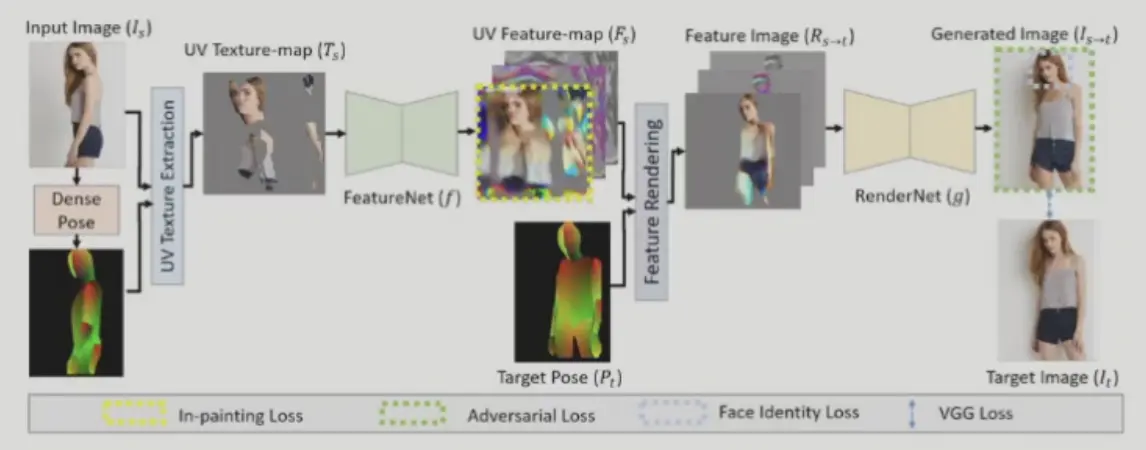
- 拟合人的参数模型,只是没有完整的纹理图
- mask 得到纹理图
- 纹理图过网络得到特征(高维纹理图)
- 纹理图特征和目标姿态参数得到特征图像
- 特征图像过网络得到最终生成图像
Note
现在的方法大致逻辑仍然一样,但大多使用了更高级的网络,例如 difussion
Head Re-Enactment#
人脸表情迁移,deepfake
AIGC#
主要得益于 diffussion model 的发展
- idea: 图像合成是在学习图像的概率分布,学习如何将高斯噪声逐渐减噪声为有意义的图像
- pros: 方便训练,分辨率较高