03 Inverted File Index
1 Intro#
- solution 1: traverse every page
- solution 2: Term-Document Incidence Matrix + Boolean Query
- problem: sparse matrix
- solution 3: Compact Version - Inverted File Index
- inverted: 正序是 file-term what terms in this file,逆序是 term-file what files contain this term
- term dict & posting list
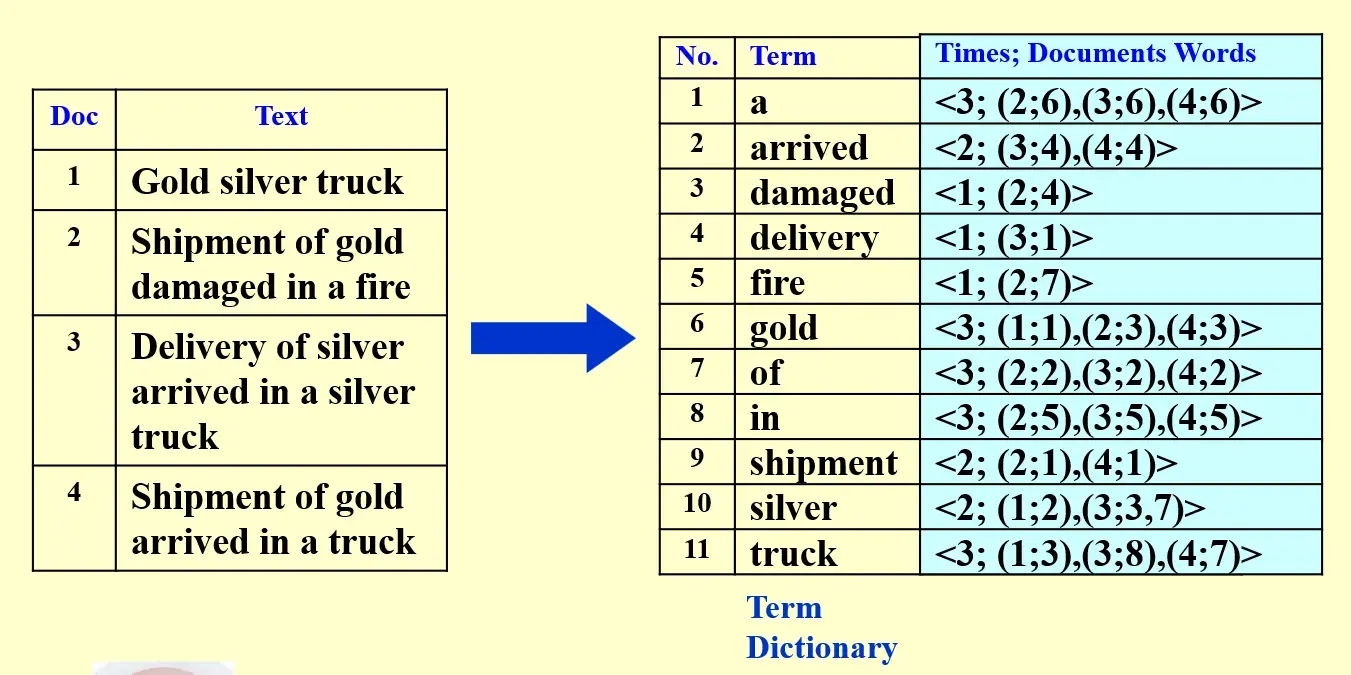
Why do we keep "times" (frequency)?
如果要进行交集查找,可以先从 frequency 较小的词开始查,减小搜索范围
且一般使用排好序的链表进行交集操作
2 Inverted file index#
2.1 Index Generator#
| index generator | |
|---|---|
2.2 problems#
- 如何定义一个 term
- 如何
Find - 如何
Insert - 如何管理大量数据
2.3 Token Analyzer & Stop Filter#
- Word Stemming: 将不同的词态还原为原本的形式
- Stop Words: 常见的 "a", "the" 等
Note
Byte Pair Encoding 能减少 tokenize 步骤丢失的信息,实现自动分词
2.4 Vocabulary Scanner#
Tries
每个节点是一个字母,常用来存单词
- solution 1: Search trees (B, B+, Trie)
- solution 2: Hashing
- pros: 查找单个单词更快
- cons: scanning in sequential order is not possible 无法范围查找(顺序查找)
2.5 Memory#
- 按照块来存储,每次内存满了就存入磁盘
- 索引结束后需要进行块合并 #CS/Algorithm/Sorting/External-Sort
2.6 Distributed indexing 分布式搜索#
- solution 1: Term-partitioned index
- solution 2: Document-partitioned index
- 一般 better
- 方便扩展
- 容灾,互联网信息存在冗余,丢失少量随机数据产生的影响小于集中的数据
2.7 Dynamic indexing#
- Auxiliary index 作为 Cache,存储一段时间内的更新和增加
- 什么时候合并?
- 如何删除?可以不进行删除 网页快照
2.8 Compression#

- Term dict 可以用单个字符串,压缩空格
- Posting list 中的位置编码可以存增量,用更少的 bit
2.9 Thresholding#
进行排序以减少搜索结果
- Document: 按照权重进行排序,只展示前 x 个文档
- cons: Boolean queries,同时进行两个单词的检索时找不到重要的文档
- Query: 按照 query 中的 term 进行排序,重要的单词是频率低的,只检索前 % 多少的 term
3 Measures for a search engine#
- index 速度
- search 速度
- 支持的 query 种类是否多样
- 用户满意度
- 数据检索性能评价
- 响应时间
- 索引范围是否够大
- 信息检索性能评价
- 另外还有找到的回答有多相关
- 数据检索性能评价
3.1 Relevance measurement#
- requires 3 elements:
- A benchmark document collection
- A benchmark suite of queries
- A binary assessment of either Relevant or Irrelevant for each query-doc pair
| Relevant | Irrelevant | |
|---|---|---|
| Retrieved | \(R_R\) (TP) | \(I_R\) (FP) |
| Not Retrieved | \(R_N\) (FN) | \(I_N\) (TN) |
- 找到的中的准确率
\[
Precision=\frac{TP}{TP+FP}
\]
- 正确的中被找到的
\[
Recall=\frac{TP}{TP+FN}
\]
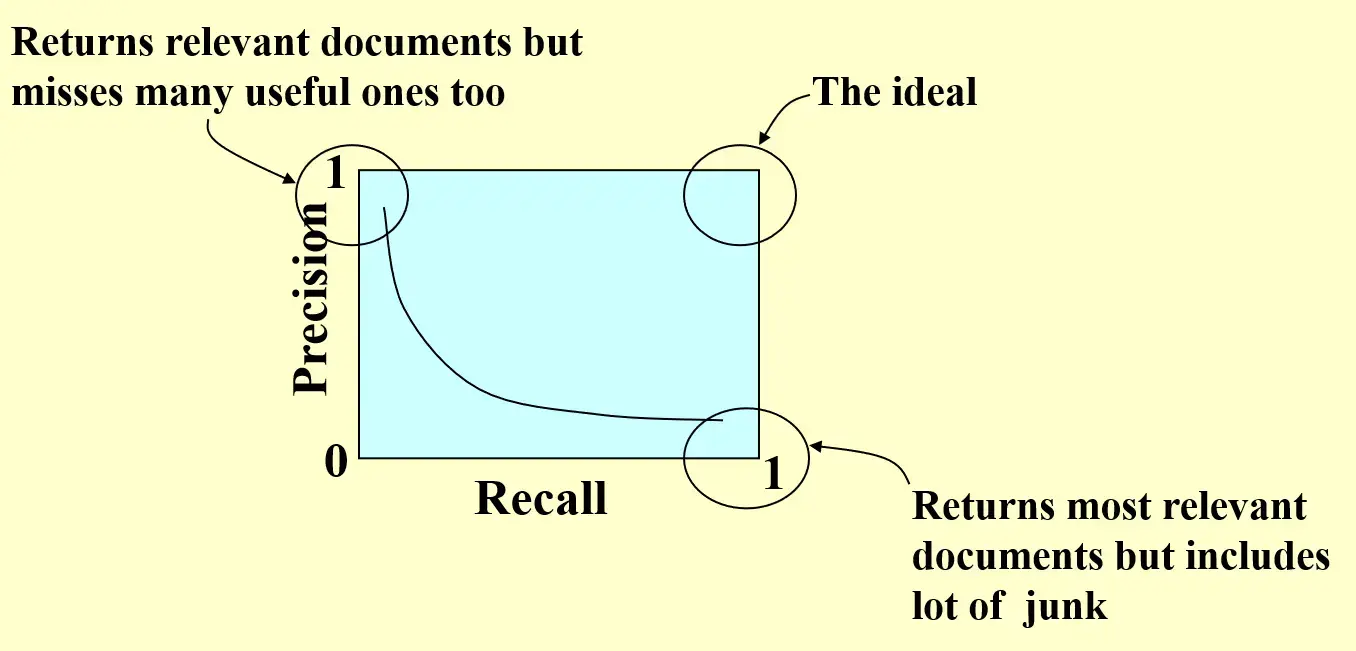
AUC
Aera under curve, 如果有多条曲线,曲线更大的更好
4 HW3#
When evaluating the performance of data retrieval, it is important to measure the relevancy of the answer set. (T/F)
Answer
F, just remember!