13 Data Storage Structures
File Organization#
- database: a collection of files
- file: a seq of records
-
record: a seq of fields
-
one approach
- 固定的 record 大小
- 每个文件只保存一种 record
- 每个 relation 都有独立的文件
- assume: 1 record 大小小于一个 block
Fixed-Length Records#
- record i starting from byte \(n\cdot (i-1)\)
- 删除的处理方式(删除 \(i\))
- 将所有后续 record 都依次向前移动 1
- 将最后一个 record 移动到 \(i\)
- 不改变其他 record,使用 freelist 管理空的位置
- 可以定期整理所有数据,保持有序
Varible-Length Records#
- e.g.
VARCHAR通过 - 维护一个 record header
- 标记所有可变长度 attr 的 offset 和 size
- 固定长度 attr 的 value
- null-value bitmap,如果是 1,表示这里是
NULL

Slotted Page Structure#
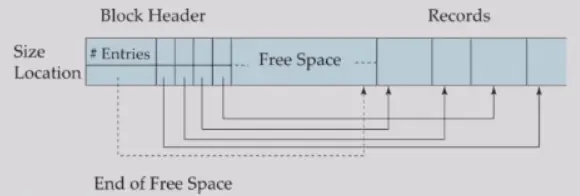
- 维护一个 slotted page header
- record entries 的数量
- free space 的最终位置
- 每个 record 的位置和大小
- slotted page header 的作用
- 解决了变长度 record 的地址无法计算的问题
Organization of Records in Files#
- heap file organization: record 可以被放在文件中任意空闲的位置
- sequential file organization: 根据每一个 record 的 search key 排序
- multitable clustering file organization
- 多表聚合,保存在同一个文件中
- motivation: store related records on the same block to minimize i/o
- B+-tree file organization: 保证顺序存储,即使有 insert/delete
- hashing file organization: 通过 hashing 将 search key 映射到 bucket 中,bucket 内大多用 heap
Heap File Organization#
-
如何快速找到有空位的地址
- 使用 Free-space map

- 保存空闲比例
- second level 可以使用 max-reduce
- 需要及时更新,但即使错误也不会带来太大问题,无非是没找到空闲位置
Sequential File Organization#
- 维护 free-list,在删除的时候将 record 加入 free-list
- 维护 overflow block,在需要插入但是对应位置没有空间(不在 free-list 中),使用指针插入
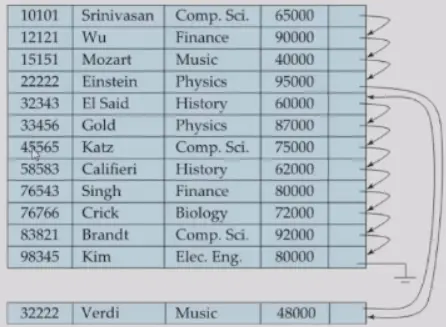
- 需要定期 reorganize
- 访问 records 的顺序和物理地址顺序不同
Multitable Clustering File Organization#
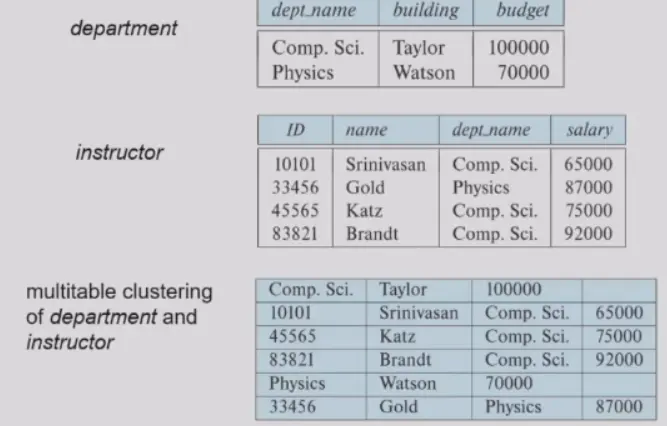
- 两张表的内容交错
- 可以按照一些 attr 做 clustering
- pros
- 减少 i/o,更大概率可以在一个 block 中访问完两张表
- 如果需要计算 join,更加方便
- cons
- 对只需要访问一张表的情况不友好
- 使用 pointer chains 来将每个 relation 的内容连接
- 导致变长度 records
- 对只需要访问一张表的情况不友好
Table Partitioning#
- e.g.
transaction_2018, transaction_2019避免出现太大的 relation - pros:
- 减少 i/o
- 方便 free space 管理
- 分布式存储(多个 SSD)
Data Dictionary Storage#
- data dict/system catalog: 保存 metadata
- info about relations
- 表的名字
- 每张表 attr 的属性
- view 名和定义
- 完整性约束
- ...
- info about relations
- 也可以使用 relation 来表示
- 需要在 db 启动时读入内存
Storage Access#
- Buffer: 主存中的一部分,用来临时存储 disk blocks 的备份
- 可以将尽量多的 blocks 放在缓冲区里,减少 i/o 数量
- Buffer manager
- 与 Cache Manager 类似,直接被程序调用,封装缓存功能
- 需要实现 buffer 分配、替换、写回策略
- Pinned blocks
- pin 所有正在读写的 block,不允许被替换
- unpin 读写完成的 block
- 支持并发操作,unpin only when
pin_count == 0
- Shared and exclusive locks on buffer
- shared lock: 允许对一个 block 的并发读
- exclusive lock: 只允许一个进程修改一个 block
- shared exclusive 不能共存
Replacement Policies#
- LRU
- motivation: 根据历史记录来预测
-
对于一些查询需求来说,并不好
- e.g. join 时,是嵌套循环,因为外层的 block 总是被替换,导致每次取用 record 都会需要重新读入 buffer
- 一种解决方法是使用 MRU(toss-immediate)
- 更进一步可以使用 tiling
- 另外也可以使用 multitable
- reorder writes
- buffer 写回磁盘时的顺序可能和 program 写请求的顺序不同
- e.g. linked list of blocks with missing block on disk
- 需要更多方法来保证写入顺序
- buffer 写回磁盘时的顺序可能和 program 写请求的顺序不同
Optimization of Disk Block Access#
- Nonvolatile write buffers: 保证写入过程不会发生意外
- Log disk
- 将 db 的所有操作保存在 non-volatile 介质上
- 由于不需要寻址,写入非常快,能够弥补写入 block 速度慢的问题
-
日志先写原则
- Journaling file systems: non-volatile 的日志文件系统
Column-Orinted Storage#
- benefits
- 只查询一些列,需要访问的数据量更小,reduct i/o
- 提升 CPU cache 命中率
- 提高压缩率,因为每一列属性一致
- 向量化处理
- drawbacks
- 针对 tuple 的操作比较麻烦
- 解压缩开销
- columnar representation 在 decision support 上更加有效
- row-orinted representation 则在事务处理上更有优势
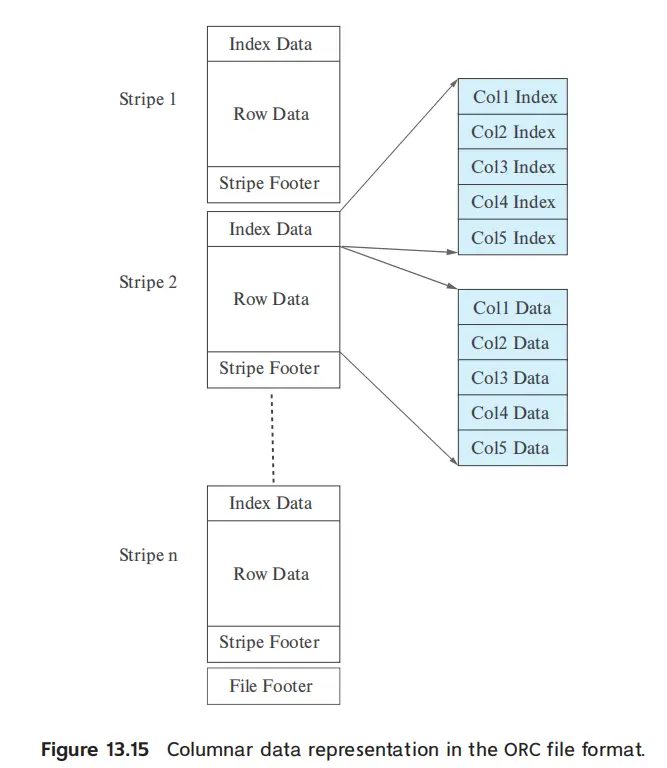
- ORC
- stripe 行组,列数据的分块
- 每个 stripe 中建立索引,列优先存储